github.com/ARM-software/ML-KWS-for-MCU
ARM-software/ML-KWS-for-MCU
Keyword spotting on Arm Cortex-M Microcontrollers. Contribute to ARM-software/ML-KWS-for-MCU development by creating an account on GitHub.
github.com
제작년부터 해보고 싶었던,, 임베디드 키워드 인식. 한글말로 모은 데이터로 구현을 해보고 싶었는데, 드디어 조금씩 진도가 나간다.
1. 모은 데이터를 1초 간격으로 자른다. 동작, 정지, 불켜줘, 불꺼줘, 등등의 단어를 모았는데, 모델에서 사용할 수 있는 1초 간격으로 자르기 위해 아래 툴을 사용하였다(아래 링크). 우분투 환경에서 컴파일 하였으며 아래 명령어로 실행할 수 있었다.
./extract_loudest_section '/home/youniechoi/Documents/Command/light_on/*.wav' /home/youniechoi/Documents/trimmed_waves/light_on
(꼭 입력 경로에 따옴표도 넣어줘야 한다..ㅠ 왜 안되지 하며 보냈던 고난의 시간들..흑)

petewarden.com/2017/07/17/a-quick-hack-to-align-single-word-audio-recordings/
-> 좀 더 찾아보니 툴 만든 분이 TinyML책을 쓰신 분이더라..역시..
A quick hack to align single-word audio recordings
As I’ve been training on the initial results of the speech gathering app, one of the challenges has been aligning the recordings. There can be a delay between somebody hitting record and sayi…
petewarden.com
2. 모은 데이터를 ARM-KWS 예제의 양식에 맞게 폴더 정리 및 파일명 변경을 수행한다. 예제에서는 라벨링의 개념을 폴더로 정의하였고 동일한 사람이 발성한 음성이 다른 사람으로 인식되어 overfitting 되는 경우를 방지하기 위해 같은 사람일 경우 '_nohash_' 를 기준으로 같은 이름으로 판별하였다.



import glob
import os
import sys
files = glob.glob('../KWS_python/Dataset/working/*')
for i, f in enumerate(files):
ftitle, fext = os.path.splitext(f)
title_split = ftitle.split('/')
print(ftitle)
#print(title_split[3])
dic_split = ftitle.split('_')
#print(dic_split[0:])
print(dic_split[0]+'_'+dic_split[1]+'_'+dic_split[2]+\
'_'+title_split[3]+'_'+dic_split[4]+'_nohash_'+dic_split[5] + fext)
os.rename(f, dic_split[0]+'_'+dic_split[1]+'_'+dic_split[2]+\
'_'+title_split[3]+'_'+dic_split[4]+'_nohash_'+dic_split[5] + fext)[파일 명 변경에 활용한 코드]
3. 준비한 데이터를 speech_dataset 폴더에 추가해 준다.

4. wanted_word에 분류를 원하는 단어로 대체하고 train.py를 돌려준다. 동작(dongjack), 정지(jeongji), 불켜(liton), 불꺼(litoff)를 구별하도록 하였다. speech_dataset에 있는 그 외의 단어는 전부 unknown으로 활용된다고 하니 그대로 두는 것이 좋을 것 같았다.

5. 드디어 학습 시작! 우와.. learning rate 은 학습률로 처음에는 0.001 과 같이 큰 수에서(초반 15000 loop) 나중에는 0.0001 로 줄어들면서(후반 3000 loop) 학습 한다고 한다. accuracy는 tensorflow안에서의 학습 정확도를 말하고 cross entrypy는 loss function으로 학습이 될 수록 줄어드는 노이즈 지표이다.
parser.add_argument(
'--how_many_training_steps',
type=str,
default='15000,3000',
help='How many training loops to run',)
parser.add_argument(
'--eval_step_interval',
type=int,
default=400,
help='How often to evaluate the training results.')
parser.add_argument(
'--learning_rate',
type=str,
default='0.001,0.0001',
help='How large a learning rate to use when training.')-> 코드에서 학습 단계별 학습률을 설정할 수 있다.

-> 400번 째 마다 Confusion matrix로 평가 한다.
6. 대략.. 세시간 이상 돌린 것 같다. 틈틈이 돌려서 정확히는 모르겠다. 아무튼 학습이 끝나고 아래와 같이 최종 정확도는 학습단계에서 98%이고 검증 데이터로 98.3% 정확도를 보이고, 최종 시험 정확도는 98.7%라고 한다.

7. tensorboard 에서 학습 그래프를 확인해 보았다. 잘 된 것 처럼 보인다..?..
tensorboard --logdir ./retrain_logs

8. 완성 된 모델을 freeze 시키고, 데이터 셋으로 테스트 해본다.
python freeze.py \--start_checkpoint=./speech_commands_train/conv.ckpt-18000 \--output_file=./yh_frozen.pb
1) 학습시키지 않은 단어를 테스트 했을 때 -> unknown(99%)

2) 학습 시킨 데이터를 테스트 했을 때 -> light off (99%)

이제 어느정도 감을 잡아, 실제 임베디드 할 모델을 만들어 보았다.
arxiv.org/pdf/1711.07128.pdf -> 논문에 설명이 잘 나와있다. 모델 크기별, 종류별 정확도를 비교 할 수 있다.
임베디드용 음성인식 예제에서는 모델 크기를 입력할 수 있게 앞서 진행했던 텐서플로우 예제를 약간 수정하였다고 한다.
ex) 3개의 3 fully-connected 레이어(각 레이어당 128개의 뉴런) 의 DNN모델을 학습 시킬때는 아래 명령어를 수행한다.
-> python train.py --model_architecture dnn --model_size_info 128 128 128
나는 논문에 나온 작은 크기의 CNN 학습 명령어로 한글 데이터를 돌려 보았다.
python train.py --model_architecture cnn --model_size_info 28 10 4 1 1 30 10 4 2 1 16 128 --dct_coefficient_count 10 --window_size_ms 40 --window_stride_ms 20 --learning_rate 0.0005,0.0001,0.00002 --how_many_training_steps 10000,10000,10000 --summaries_dir work/CNN/CNN1/retrain_logs --train_dir work/CNN/CNN1/training
first_filter_count = model_size_info[0] # 28
first_filter_height = model_size_info[1] #time axis 10
first_filter_width = model_size_info[2] #frequency axis 4
first_filter_stride_y = model_size_info[3] #time axis 1
first_filter_stride_x = model_size_info[4] #frequency_axis 1
second_filter_count = model_size_info[5] 30
second_filter_height = model_size_info[6] #time axis 10
second_filter_width = model_size_info[7] #frequency axis 4
second_filter_stride_y = model_size_info[8] #time axis 2
second_filter_stride_x = model_size_info[9] #frequency_axis 1
linear_layer_size = model_size_info[10] 16
fc_size = model_size_info[11] 128
아마 아래와 같은 이미지로 구성된 모델로 보인다. (pooling은 제외하고!) 첫번째 컨벌루젼 필터의 갯수는 28개이고, 가로 세로 10*4에 1칸씩 좌우로 움직이며 필터링 한다.
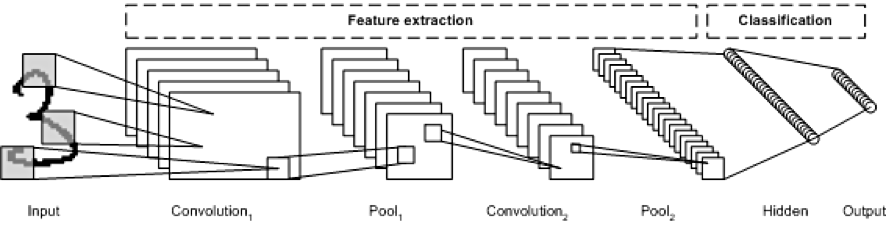
def create_cnn_model(fingerprint_input, model_settings, model_size_info,
is_training):
"""Builds a model with 2 convolution layers followed by a linear layer and
a hidden fully-connected layer.
model_size_info: defines the first and second convolution parameters in
{number of conv features, conv filter height, width, stride in y,x dir.},
followed by linear layer size and fully-connected layer size.
"""
if is_training:
dropout_prob = tf.placeholder(tf.float32, name='dropout_prob')
input_frequency_size = model_settings['dct_coefficient_count']
input_time_size = model_settings['spectrogram_length']
fingerprint_4d = tf.reshape(fingerprint_input,
[-1, input_time_size, input_frequency_size, 1])
first_filter_count = model_size_info[0]
first_filter_height = model_size_info[1] #time axis
first_filter_width = model_size_info[2] #frequency axis
first_filter_stride_y = model_size_info[3] #time axis
first_filter_stride_x = model_size_info[4] #frequency_axis
second_filter_count = model_size_info[5]
second_filter_height = model_size_info[6] #time axis
second_filter_width = model_size_info[7] #frequency axis
second_filter_stride_y = model_size_info[8] #time axis
second_filter_stride_x = model_size_info[9] #frequency_axis
linear_layer_size = model_size_info[10]
fc_size = model_size_info[11]
# first conv
first_weights = tf.Variable(
tf.truncated_normal(
[first_filter_height, first_filter_width, 1, first_filter_count],
stddev=0.01))
first_bias = tf.Variable(tf.zeros([first_filter_count]))
first_conv = tf.nn.conv2d(fingerprint_4d, first_weights, [
1, first_filter_stride_y, first_filter_stride_x, 1
], 'VALID') + first_bias
first_conv = tf.layers.batch_normalization(first_conv, training=is_training,
name='bn1')
first_relu = tf.nn.relu(first_conv)
if is_training:
first_dropout = tf.nn.dropout(first_relu, dropout_prob)
else:
first_dropout = first_relu
first_conv_output_width = math.ceil(
(input_frequency_size - first_filter_width + 1) /
first_filter_stride_x)
first_conv_output_height = math.ceil(
(input_time_size - first_filter_height + 1) /
first_filter_stride_y)
# second conv
second_weights = tf.Variable(
tf.truncated_normal(
[second_filter_height, second_filter_width, first_filter_count,
second_filter_count],
stddev=0.01))
second_bias = tf.Variable(tf.zeros([second_filter_count]))
second_conv = tf.nn.conv2d(first_dropout, second_weights, [
1, second_filter_stride_y, second_filter_stride_x, 1
], 'VALID') + second_bias
second_conv = tf.layers.batch_normalization(second_conv, training=is_training,
name='bn2')
second_relu = tf.nn.relu(second_conv)
if is_training:
second_dropout = tf.nn.dropout(second_relu, dropout_prob)
else:
second_dropout = second_relu
second_conv_output_width = math.ceil(
(first_conv_output_width - second_filter_width + 1) /
second_filter_stride_x)
second_conv_output_height = math.ceil(
(first_conv_output_height - second_filter_height + 1) /
second_filter_stride_y)
second_conv_element_count = int(
second_conv_output_width*second_conv_output_height*second_filter_count)
flattened_second_conv = tf.reshape(second_dropout,
[-1, second_conv_element_count])
# linear layer
W = tf.get_variable('W', shape=[second_conv_element_count, linear_layer_size],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.get_variable('b', shape=[linear_layer_size])
flow = tf.matmul(flattened_second_conv, W) + b
# first fc
first_fc_output_channels = fc_size
first_fc_weights = tf.Variable(
tf.truncated_normal(
[linear_layer_size, first_fc_output_channels], stddev=0.01))
first_fc_bias = tf.Variable(tf.zeros([first_fc_output_channels]))
first_fc = tf.matmul(flow, first_fc_weights) + first_fc_bias
first_fc = tf.layers.batch_normalization(first_fc, training=is_training,
name='bn3')
first_fc = tf.nn.relu(first_fc)
if is_training:
final_fc_input = tf.nn.dropout(first_fc, dropout_prob)
else:
final_fc_input = first_fc
label_count = model_settings['label_count']
final_fc_weights = tf.Variable(
tf.truncated_normal(
[first_fc_output_channels, label_count], stddev=0.01))
final_fc_bias = tf.Variable(tf.zeros([label_count]))
final_fc = tf.matmul(final_fc_input, final_fc_weights) + final_fc_bias
if is_training:
return final_fc, dropout_prob
else:
return final_fc
아, 그런데 임베디드 예제가 dnn 과 ds-cnn모델만 구현되어 있다...그래서 다시 dnn으로 학습 시작..
python train.py --model_architecture dnn --model_size_info 144 144 144 --dct_coefficient_count 10 --window_size_ms 40 --window_stride_ms 40 --learning_rate 0.0005,0.0001,0.00002 --how_many_training_steps 10000,10000,10000 --summaries_dir ./work/DNN/DNN1/retrain_logs --train_dir work/DNN/DNN1/training
dnn은 훨씬 간단하다. 3개의 레이어를 형성하고 각 레이어별 weight와 bias값 산출한다.
def create_dnn_model(fingerprint_input, model_settings, model_size_info,
is_training):
"""Builds a model with multiple hidden fully-connected layers.
model_size_info: length of the array defines the number of hidden-layers and
each element in the array represent the number of neurons
in that layer
"""
if is_training:
dropout_prob = tf.placeholder(tf.float32, name='dropout_prob')
fingerprint_size = model_settings['fingerprint_size']
label_count = model_settings['label_count']
num_layers = len(model_size_info)
layer_dim = [fingerprint_size]
layer_dim.extend(model_size_info)
flow = fingerprint_input
tf.summary.histogram('input', flow)
for i in range(1, num_layers + 1):
with tf.variable_scope('fc'+str(i)):
W = tf.get_variable('W', shape=[layer_dim[i-1], layer_dim[i]],
initializer=tf.contrib.layers.xavier_initializer())
tf.summary.histogram('fc_'+str(i)+'_w', W)
b = tf.get_variable('b', shape=[layer_dim[i]])
tf.summary.histogram('fc_'+str(i)+'_b', b)
flow = tf.matmul(flow, W) + b
flow = tf.nn.relu(flow)
if is_training:
flow = tf.nn.dropout(flow, dropout_prob)
weights = tf.get_variable('final_fc', shape=[layer_dim[-1], label_count],
initializer=tf.contrib.layers.xavier_initializer())
bias = tf.Variable(tf.zeros([label_count]))
logits = tf.matmul(flow, weights) + bias
if is_training:
return logits, dropout_prob
else:
return logits
2021.02.12 - [분류 전체보기] - [ARM KWS] 임베디드 키워드 인식_(2) Weight Quantization
'개발 기록' 카테고리의 다른 글
| 개인정보처리방침 (0) | 2023.07.19 |
|---|---|
| [AWS] OpenProject 아마존 웹서버에 설치하기 (0) | 2020.09.06 |